

hitctf2024-week4-writeup-notes
Reverse
ezVM
一眼模拟指令集,Z3 启动
Confusion
花指令一号之 jmp -> jz + jnz,nop 中段的多余字节码恢复
NepCTF 的超级大号 obf:https://mp.weixin.qq.com/s/W9c87MXbVBdUOTY8gAtKsA
OldEight
dnSpy 反编译 C# 工具链
NepCTF 的时候遇到了通过 il2cpp 生成的 Unity 应用,此时不能直接用 dnSpy,需要用 il2cppdumper 之类的工具
Crypto
格密码专场,可恶的数学
Lattice-1
有 c = (a * m) mod p,给定 c 和 p 求 m
推式子
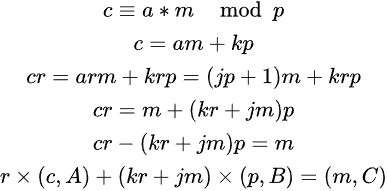
因此构造如下的格矩阵
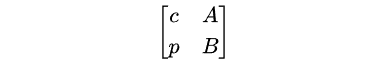
令 A = 1, B = -1,规约后可以得到对应的 (m, C)
Trivia: 此处的 C 可以用于联立解出先前的 r
Lattice-2
一个很巧妙的轮换构造,三个参数也是这个结构下所需要的
d' * e' = 1 + kabcdef,根据 n1, n2, n3 的特点可以转化为三个形如 d' * e' + An[i] = B 的等式,构造格求解得到 d',由 d' * e' = 1 + kabcdef = 1 (mod phi(n1)) 完成 RSA 解密
1 | |
精彩之处在于此处对于大小为 k 的格,其在 Hermit 定理中的决定值大约在 (B + 0x600) * (k-1) / k bit,而目标向量的大小在 max(0x210, 0x510 + B) bit,此时 k = 3 是存在能够用于配平 Hermit 定理的 B 的最小值。
Lattice-3
究极暴力之我寻思应该能行之力
可以将加密过程改写如下:C = M * T mod p,进而通过 seed 得到 16 个已知的 C[i]。因此尝试根据如下恒等式构造格:
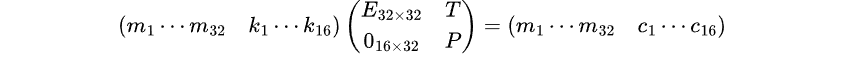
其中 T 为根据已有的 C 截取的系数矩阵。会发现这个格无论如何缩放都无法满足 Hermit 定理的要求,故进一步将格改为如下的格:
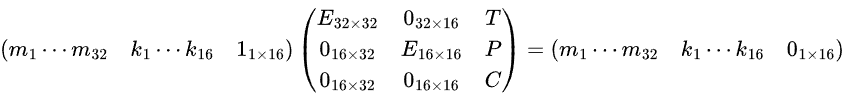
根据构造,由于明文为 ASCII,其大小约为 8 bit,而 k 为 线性组合之和除以 p 的商,大小一般在 8 + 5 = 13 bit,左边格的决定式如下,大约为 35 bit(在这组数据下大约为 34.67 bit),故可以直接进行规约,结果的第一行即为所求答案。
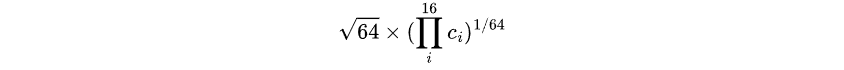
1 | |
Pwn
IOFILE
write 不能覆写,而且没有 free 无法 UAF,但是 read 和 write 中对 idx 的检查存在漏洞。
IDA 发现 bss 段的开头有一个指向自己的 __dso_handle,因此可以通过这个地址进行负 idx 的读写来 leak 其它地址。在这后面紧跟的是 stdout, stdin 和 stderr 三个指针,分别指向 libc 中的 _IO_2_1_stdout_, _IO_2_1_stdin_ 和 _IO_2_1_stderr_,可以用于计算 libcbase,进而得到 __environ 的地址,其中存储的是一个指向栈上的存储环境变量的指针数组,因此可以得到栈地址。通过负 idx 写来伪造一个任意地址写就能完成 onegadget 的注入,得到 flag。
后半段可能还可以通过覆盖 _IO_2_1_stdout_ 的 vtable 来注入 onegadget?不能直接注入,因为 libc >= 2.24,会触发 Fatal error: glibc detected an invalid stdio handle
https://ctf-wiki.org/pwn/linux/user-mode/io-file/exploit-in-libc2.24/#_io_str_jumps-overflow
可以将 vtable 修改为此处的 _IO_str_jumps,然后修改 _IO_2_1_stdout_ 来触发 shell
LargeBinAttack
方法好像蛮多的,先试了一下 House of Banana,具体来说就是利用 largebin attack 更改 ld 中的 _rtld_global._dl_ns->_ns_loaded,这是一个程序通过 exit 等流程退出之后在 ld 中的 _dl_fini 会检查、处理并执行的链表。正常情况下,这个链表一共有四项,其第 1、2、4 项位于 ld 段内,第 3 项位于 mmap 出的段内,这意味着最常用的攻击方式是修改第一项到可控制的地址上,在此处便是 largebin attack 的堆段内。伪造的 link_map 结构可以执行一系列的函数,其特点是对应的 gadget 需要倒序插入(对应 _dl_fini 中的 while(--i))。参数规则似乎需要自行寻找对应的 gadget。接下来的部分在于不同机器在开启 ASLR 之后 libc 段与 ld 段之间偏移值的第 13~20 位需要进行爆破,因此需要将 ld 中的偏移使用 ld 内的地址,分别计算每次的 ld_base,最后再一起计算 _ns_loaded_addr 和 link_map_2_addr。